本文最后更新于:星期二, 六月 16日 2020, 3:08 下午
这一周主要是配置Hadoop的相关环境,配个环境心态差点给我配崩掉
Hadoop学习之配置Hadoop
(一)环境配置
- 工具:VMWare WorkStation12 Pro
- 环境:Kali Linux 2018.3a(x64)(下载地址:https://www.kali.org/downloads/ )
马上就遇到的坑(窒息)
准备往VM中安装Kali Linux时,我发现VM不能自动识别系统镜像所包含的系统,只能自己选择,但是我下载Kali是2018.3a版本的,使用的是Linux 4.x的内核,选项中最高支持到3.x内核。没办法不想重新下一个VM14,只能先硬着头皮安装,看看会不会出什么问题。
读取镜像,然后给虚拟机划分虚拟内存及磁盘。
然后打开虚拟机进行系统的安装引导。
安装成功!好像也并没有发现什么问题。这个伏笔就先埋着吧,接下来还是赶紧配置一下HDFS
(二)HDFS安装
- 参考教程:https://www.yiibai.com/hadoop/hadoop_enviornment_setup.html
创建一个独立用户
创建一个独立用户是为了将Hadoop文件系统从Unix文件系统中隔离开来,步骤如下: - 使用 “su” 命令开启root
- 创建用户从root帐户使用命令 “useradd username”
- 使用命令打开一个现有的用户帐户“su username”

SSH设置和密钥生成
SSH设置需要在集群上做不同的操作,如启动,停止,分布式守护shell操作。认证不同的Hadoop用户,需要一种用于Hadoop用户提供的公钥/私钥对,并用不同的用户共享。
下面的命令用于生成使用SSH键值对。复制公钥形成 id_rsa.pub 到authorized_keys 文件中,并提供拥有者具有authorized_keys文件的读写权限。
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys这一部分的坑
- 当我在Kali Linux中新建用户后,发现无法用该用户登入图形界面,遂查找了一下解决方案,发现新建可用于图形界面的用户与普通用户所用的命令是不同的。一个是useradd,一个是 adduser 。useradd添加的用户可以使用SSH登录(解决方案:https://blog.csdn.net/zxx2011082427/article/details/51932718 )
- 然鹅新建用户也没有用,当我在hadoop用户下执行 ssh-keygen -t rsa 系统提示 permission denied 但ssh用户我又不敢给它过多的权限,于是我仅在 /home/hadoop 文件夹下赋予其写权限
成功生成SSH键值对!root@DiaosSama:~# chown -R hadoop:hadoop /home/hadoop root@DiaosSama:~# chmod 760 /home/hadoop
(参考资料:https://blog.csdn.net/weiyangdong/article/details/80323661 )
但是
紧接着我发现,Kali Linux上没有rpm包,没有ssh client,也没有ssh server。。
导致我在配置SSH无密钥登录时一直连接不上本地主机,我还以为是我的ssh密钥配置出现了偏差。。
这个坑一坑就是一个多小时,最后发现问题,只能更换Linux版本,换成 CentOS 7,重新配置SSH无密钥登录(这东西差点把我弄的当场自闭)
(参考资料:https://www.cnblogs.com/xzjf/p/7231519.html )
安装CentOS 7
(下载地址:http://isoredirect.centos.org/centos/7/isos/x86_64/CentOS-7-x86_64-DVD-1804.iso )
结果…我花了大半天下下来一个centos everything的镜像,VMware无法从boot安装!经过多次上网考证,最终发现自己要下DVD版的才能安装在VMware里…今天真的是踩坑无数…
CentOS下配置SSH
(参考资料:https://www.cnblogs.com/xzjf/p/7231519.html )
首先仍然是创建hadoop用户,原因上部分有提到
[root@localhost ~]# useradd -m hadoop -s /bin/bash #创建新用户,并使用/bin/bash 作为shell [root@localhost ~]# passwd hadoop #更改密码为用户增加管理员权限
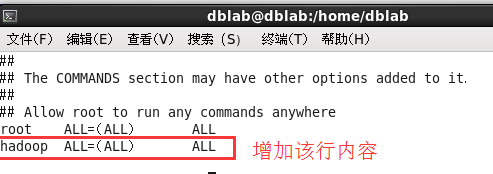
# visudo如下图,找到 root ALL=(ALL) ALL 这行(应该在第98行,可以先按一下键盘上的 ESC 键,然后输入 :98 (按一下冒号,接着输入98,再按回车键),可以直接跳到第98行 ),然后在这行下面增加一行内容:hadoop ALL=(ALL) ALL (当中的间隔为tab),如下图所示:
配置SSH无密码登录
首先测试SSH是否可用:[hadoop@localhost ~]$ ssh localhost #连接到本地然后输入exit退出刚刚的ssh,回到终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中
[hadoop@localhost ~]$ exit #退出刚才的ssh localhost [hadoop@localhost ~]$ cd ~/.ssh/ #若没有该目录,请先执行一次ssh localhost [hadoop@localhost .ssh]$ ssh-keygen -t rsa #会有提示,都按回车就可以 [hadoop@localhost ~]$ cat id_rsa.pub >> authorized_keys #加入授权 [hadoop@localhost ~]$ chmod 600 ./authorized_keys #修改文件权限安装JAVA
下载解压JDK
[hadoop@localhost ~] sudo yum install java-1.7.0-openjdk java-openjdk-devel结果再次踩坑
输入命令后,系统提示:
Loaded plugins: fastestmirror, langpacks One of the configured repositories failed (Unknown), and yum doesn't have enough cached data to continue. At this point the only safe thing yum can do is fail. There are a few ways to work "fix" this: 1. Contact the upstream for the repository and get them to fix the problem. 2. Reconfigure the baseurl/etc. for the repository, to point to a working upstream. This is most often useful if you are using a newer distribution release than is supported by the repository (and the packages for the previous distribution release still work). 3. Disable the repository, so yum won't use it by default. Yum will then just ignore the repository until you permanently enable it again or use --enablerepo for temporary usage: yum-config-manager --disable <repoid> 4. Configure the failing repository to be skipped, if it is unavailable. Note that yum will try to contact the repo. when it runs most commands, so will have to try and fail each time (and thus. yum will be be much slower). If it is a very temporary problem though, this is often a nice compromise: yum-config-manager --save --setopt=<repoid>.skip_if_unavailable=true猜想可能是网络不通,遂ping各路域名:
[hadoop@localhost ~]$ ping www.baidu.com ping: www.baidu.com: Name or service not known [hadoop@localhost ~]$ ping 8.8.8.8 connect: Network is unreachable应该是网卡没有配好,虚拟机连不上网
(CentOS真的8行)
然后…我尝试了网上各种恢复CentOS 7网络连接的方法…却一直没能成功
终于
尝试了无数种方法后有一种奏效了!(解决方案:https://blog.csdn.net/sdd220/article/details/80306730 )
然后发现只能解析ip地址无法解析域名,那就是DNS服务器的问题了
于是再添加了几个备用DNS(解决方案:https://blog.csdn.net/sdd220/article/details/80306730 )
再次执行安装java的命令
成功了!!!!(泪流满面.jpg)
安装Hadoop 2.6.5
在优秀同学的推荐下,找到了一个非常不错的教程。
折腾了一下把我的CentOS 7装上了图形界面,去到镜像站 http://mirrors.cnnic.cn/apache/hadoop/common/ 下载了hadoop2.6.5 开始着手安装
按照教程中介绍的方法,我很快便成功安装上了hadoop 2.6.5
接下来终于可以试手了
Hadoop单机配置(非分布式)
Hadoop 默认模式为非分布式模式,无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
首先我们可以运行Hadoop自带的丰富例子
[hadoop@bogon hadoop]$ ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar可以看到所有例子,包括wordcount、terasort、join、grep等
Hadoop伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
在设置 Hadoop 伪分布式配置前,我们还需要设置 HADOOP 环境变量,执行如下命令在 ~/.bashrc 中设置:
$ gedit ~/.bashrc这次我们选择用 gedit 而不是 vim 来编辑。gedit 是文本编辑器,类似于 Windows 中的记事本,会比较方便。保存后记得关掉整个 gedit 程序,否则会占用终端。在文件最后面增加如下内容:
# Hadoop Environment Variables
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin保存后,不要忘记执行如下命令使配置生效:
$ source ~/.bashrc这些变量在启动 Hadoop 进程时需要用到,不设置的话可能会报错(这些变量也可以通过修改 ./etc/hadoop/hadoop-env.sh 实现)。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
修改配置文件 core-site.xml (通过 gedit 编辑会比较方便: gedit ./etc/hadoop/core-site.xml),将当中的
<configuration>
</configuration>修改为下面配置
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>同样的,修改配置文件 hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>配置完成后,执行 NameNode 的格式化:
$ ./bin/hdfs namenode -format后续执行教程中的操作,便看到了理想的输出结果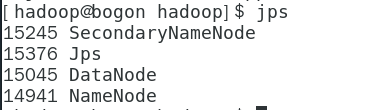
在web界面输入 http://localhost:50070 在web界面上查看hadoop进程
小结
历经千辛万苦,靠着网络上各路大神的博客教程,我一个小白在对Hadoop了解甚少的情况下终于配置出了本机的Hadoop伪分布式。看着鼓捣了好几天的hadoop终于运行了起来,心中还是蛮有成就感的。
说实话,研究一些自己完全不懂的东西的时候,还是要学会善用搜索引擎,有许多问题还是能够自行解决的,及时中间会走很多弯路,那最后它也会变成你的知识储备嘛。
好了弯路走的还是有点多,接下来要加快对Hadoop其他方面知识的学习了。
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!